
Research project: Developing Deep Learning Architecture for Imaging of Subsurface structures
Dr.rer.nat. Ir. Wahyudi Widyatmoko Parnadi, MS.
Program Studi Teknik Geofisika
Kelompok Keahlian Geofisika Terapan dan Eksplorasi
Background
In line with the booming of construction works in Indonesia, detailed information of the subsurface condition of the ground supplied from geotechnical as well as from geophysical works are required. Failed attempts to image exact location, position and geometry of man-made substructures like concrete water tunnel, metal pipes and cables as well as geological features at construction sites can lead to rise risk level for the completion time of the infrastructure construction. The risk level increases as materials or objects like toxic contaminants plumes or high voltage electric cables (for examples 150KV electric cables) exists underground. Appropriate, cost effective and safe tool to illuminate such objects is then extremely required. To solve such a problem, we use Ground-penetrating radar (GPR) technique that is appropriate tool for that purpose, with detectable objects ranging from surface until the depth of 20 meters, depending on used antenna frequencies. Subsurface utilities, like pipes and cables, whose dimensions are smaller than the wavelength appear in the travel-time GPR profile as a diffraction hyperbolic curve. In reality, such hyperbolic curve is difficult to recognize. It has narrower shape due to complexity in the electromagnetic properties and earth model of shallow subsurface and also due to systematic and ambient noise existence. Therefore an appropriate technique in GPR to accurately and precisely segment underground structures and delineate boundaries need to be developed.
Research goal
The research is aimed at the application of machine learning and deep learning for GPR, specifically developing a novel new deep learning architecture for radar image segmentation and boundary prediction.
Research team
We focus our research in solving such problem in the time period of 2019 – 2021. Our research team consists of one Associate Professor as team leader; one Associate Professor, two Assistant Professors, one visiting researcher (researcher at Univ. of Tokyo) and two master students as team member. Research team is supported by one Professor from Chiba University of Japan.
Prior works using GPU
One of our researchers led research in developing the Entropic Lattice Boltzmann (ELBM) model for non-Newtonian Fluid. Validation is given by simulating the ELBM model in the case of turbulent flow in lid-driven cavity, for non-Newtonian fluid obeying Power-Law. He created two simulation program implementations: with C ++ for simulation on the CPU, and with C CUDA for parallel computing on simulation on the GPU. The simulation results are analyzed for their numerical accuracy and stability, and compared with other methods in the area of the Large Eddy Simulation. To speed up the simulation, a parallel computing implementation on the GPU is given. The ELBM implementation is performed on the CPU and GPU, and the computational time required for 100,000 iterations is compared. The CPU used is Intel (R) Core (TM) i7-3612QM, while the GPU used is the Nvidia GeForce GTX 660. The results of the implementation of parallel computing on the GPU show a far better performance than the CPU implementation, with the GPU implementation resulting in a 57x speedup.
Current & future works
Our current research focuses on developing novel new deep learning architectures for Ground Penetrating Radar (GPR) image segmentation and boundary prediction. Radar images have their own characteristics very distinct from optical images, thus the established deep learning architectures designed for image segmentation are inadequate. We have done some preliminary works with a few novel experimental architectures, and the results are extremely promising, and potentially quite a breakthrough in our domain.
We are conducting multiple experiments using synthetic and real-world datasets. For synthetic datasets, we generate synthetic radar images through Finite Difference Time Domain (FDTD) simulation. For each experiment using synthetic data, we generate a dataset of 1400 ground models, which we split into training, validation, and test sets.
Deep Learning Architecture
The Deep Learning architecture is based on U-Net [(Ronneberger, 2015), as illustrated in figure (1). This architecture consists of a contracting path and an expansive path, with skip connections across each contracting block to each corresponding expansive block of the same size. The contracting path consists of a series of contracting blocks, illustrated in figure (2.a). The expansive path consists of a series of expansive blocks, illustrated in figure (2.b). The network ends with a 1×1 Convolution with 1 filter in order to make it a binary classification, followed by sigmoid activation function.
Each contracting block halves the spatial resolution, while doubling the number of filters. Meanwhile each expansive block doubles the spatial resolution, while halving the number of filters. The number of filters in the first contracting block is chosen to be 32. By the time it hits the center block, the number of filters is 1024.
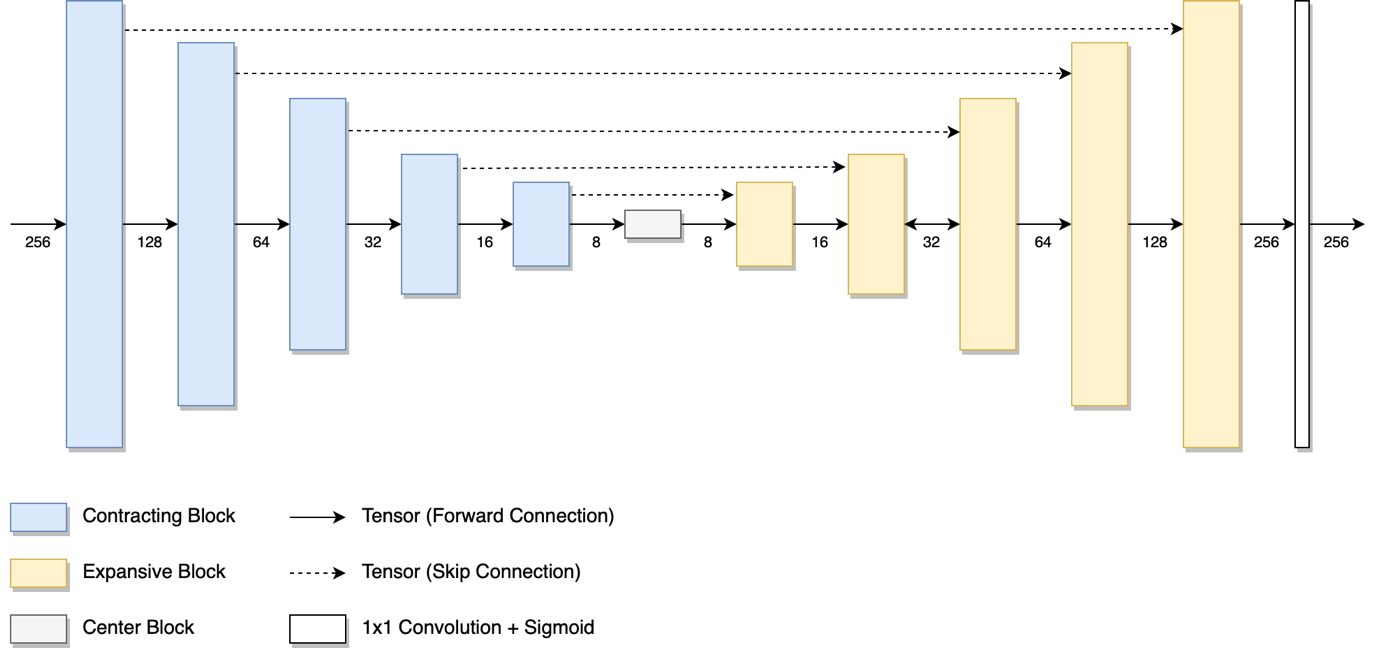
Figure 1. U-Net architecture
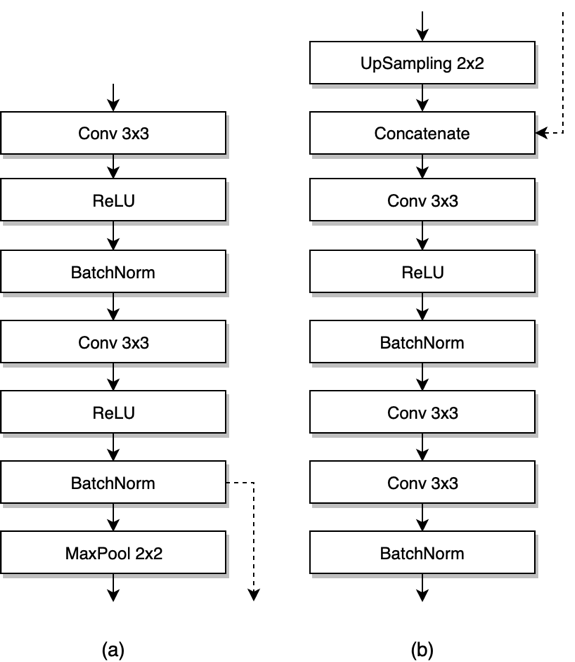
Figure 2. Contracting block (a) and expansive block (b)
Datasets
This study consists of two experiments (“Experiment A” and “Experiment B”) with two corresponding datasets. Both datasets are synthetically generated using the open-source software gprMax [gprmax2016]. For each dataset, we randomly generate 100 ground truth earth models, and simulate the resulting GPR B-scans. We split that into 80 models for training and 20 models for testing. Each ground truth model is a half-space cross-section of 5mx5m, with dx, dy, and dz of 1cm, resulting in a 500×500 grid.
As data augmentation, each ground truth model and its corresponding B-scan is cropped non-randomly into 5 sub-models, and further augmented by horizontal flipping. Each sub-model is resized to a 256×256 grid. This results in augmented 10 models for each simulated model.
As a result, we have 800 ground truth models and their corresponding B-scans for training, and 200 ground truth models and their corresponding B-scans for testing.
Experiment A
For this experiment, each model is a homogenous soil with 5 randomly positioned steel pipes inside the 5mx5m cross section. 3 of the pipes have a diameter of 40 cm, while 2 of them have a diameter of 20 cm. Pipes are made sure to never overlap, with minimum separation of 10 cm.
The target for the machine learning algorithm is to predict the positions and sizes of the pipe, from the resulting preprocessed B-Scan.
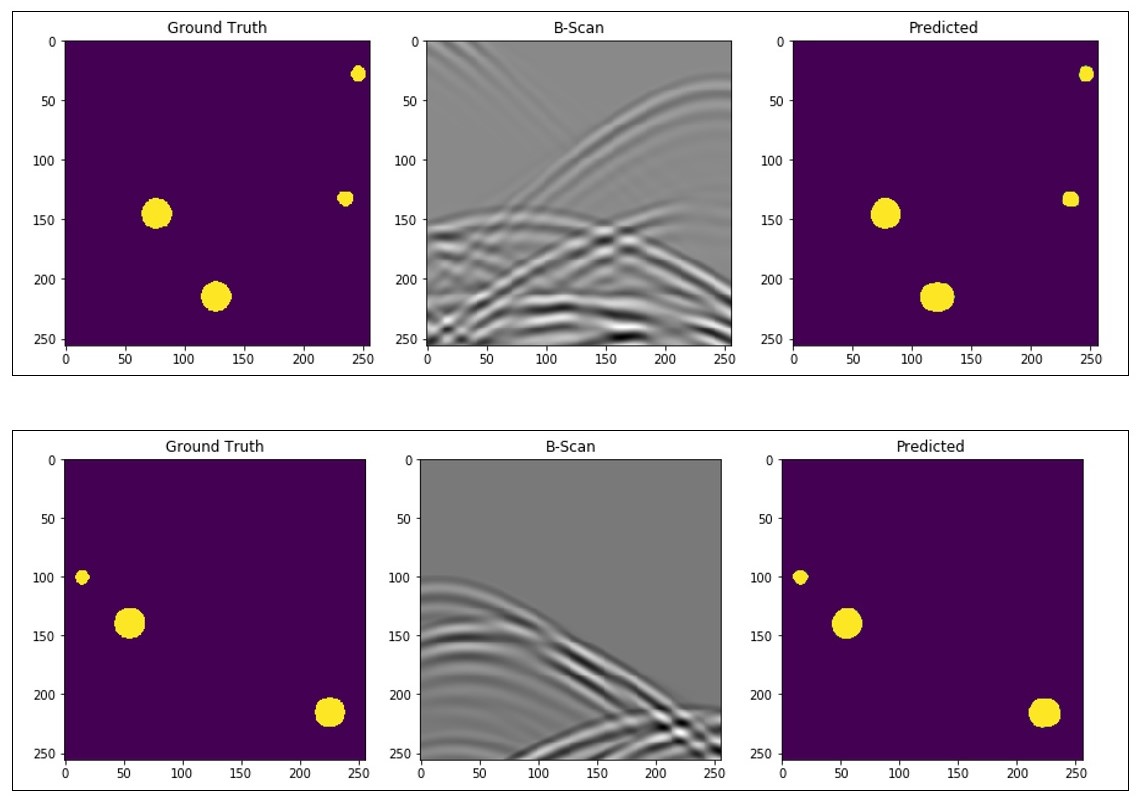
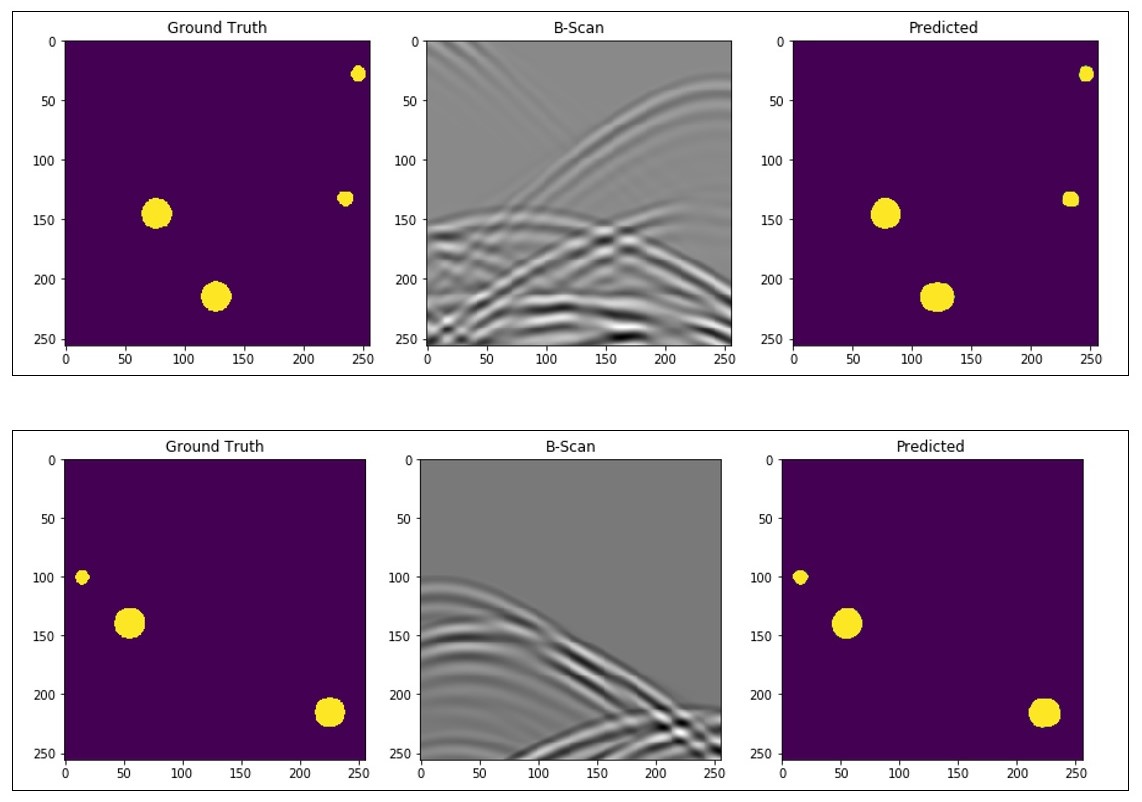
Figure 3. Results showing the ground truth model (left), resulting B-Scan (middle), and the machine learning prediction (right).
The results (fig.3) show remarkable prediction accuracy in detection, location and size of the pipes from the B-Scans, even in convoluted and hard to interpret areas. Inference on the test set, we acquired average Dice coefficient of 0.7056 and average Intersection over Union (IoU) score of [INSERT IOU SCORE], and accuracy of [INSERT ACCURACY SCORE], showing great correspondence between ground truth and predicted maps.
Challenges
Our biggest bottlenecks lie in two areas: the first is generating the synthetic radargrams through FDTD simulation. We are currently using a CPU implementation, which takes a tremendous, often infeasible amount of time. For a 500 by 500 resolution grid, simulating 1400 models takes 96 compute-days on an 8 vCPU machine (“n1-highcpu-8” instance on Google Cloud Platform). By offloading this work to the GPU, it will massively speed up this process. The second bottleneck is in experimenting with different configurations of the proposed architectures. Having a powerful GPU for training and evaluating the various models will be extremely beneficial. Therefore some GPUs for computing implementation are required.
Expected outcome & timeline
Our expected outcome will be the first deep learning architecture developed for Ground Penetrating Radar. To the best of our knowledge, this has never been done before. The resulting proposed architecture can potentially scale to other domains where images exhibit similar characteristics of significant non-locality, i.e. Synthetic Aperture Radar (SAR) images, ultrasound images, to name a few. We plan to publish this in one of several potential journals.
First draft of the new proposed architecture is planned in early 2020, and submission to potential journals is planned by mid 2020. If the research proves to be a success, we have plans for more application of deep learning within our domain until 2021.
References
- Olaf Ronneberger, Philipp Fischer, Thomas Brox. (2015). U-Net: Convolutional Networks for Biomedical Image Segmentation. U-Net: Convolutional Networks for Biomedical Image Segmentation. In MICCAI 2015. arXiv:1505.04597v1
- Sergey Ioffe, Christian Szegedy. (2015). Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv:1502.03167
- Shibani Santurkar, Dimitris Tsipras, Andrew Ilyas, Aleksander Madry. (2018). How Does Batch Normalization Help Optimization? In NeurIPS 2018. arXiv:1805.11604
- Craig Warren, Antonios Giannopoulos, Iraklis Giannakis. (2016). gprMax: Open source software to simulate electromagnetic wave propagation for Ground Penetrating Radar. Computer Physics Communications. 209, 163-170.
- Gary King, Langche Zeng. (2001). Logistic Regression in Rare Events Data. Political Analysis, 9, Pp. 137-163.
- Fausto Milletari, Nassir Navab, Seyed-Ahmad Ahmadi. (2016). V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. arXiv:1606.04797